

In this guide, we will explore what a data pipeline is, why it is essential for modern businesses, and how it helps organizations manage and process their data efficiently. A data pipeline is a series of processes and tools that allow raw data to be collected, processed, and delivered to a destination where it can be analyzed and utilized.
Centric specializes in designing and managing complex data systems that ensure seamless data flow, transformation, and storage for businesses looking to gain insights and make data-driven decisions.
In this article, you'll learn about the components of a data pipeline, the different types available, how to build one, and the key challenges involved in implementing these systems. Whether you're new to data engineering services or looking to optimize your existing systems, this guide will provide valuable insights to help you navigate the world of data pipelines
What Are Data Pipelines and Why Do They Matter?
Data pipelines are a crucial part of modern data-driven organizations, allowing businesses to seamlessly collect, process, and integrate data from various sources. These pipelines transform raw, unstructured data into usable information, enabling businesses to make informed decisions and drive operational efficiency.

Without an efficient data pipeline, organizations risk fragmented data across different systems, leading to inconsistent insights and delayed decision-making.
As businesses increasingly rely on multiple tools and platforms for data collection, having a streamlined data pipeline ensures the integration of all data into a central system, where it can be analyzed and leveraged for actionable insights.
Overcoming Data Silos
Data silos refer to isolated systems or platforms that store data independently, making it difficult to gain a unified view of business operations. Data pipeline architecture helps break down these silos by ensuring that data from different sources is collected and consolidated into a central repository, where it can be analyzed and acted upon efficiently.
By connecting fragmented data sources, pipelines empower businesses to extract valuable insights from across their organization. This unified data allows decision-makers to make informed choices and helps organizations improve their ETL process (Extract, Transform, Load), ensuring that the data is accurate, clean, and ready for analysis.
Real-Time vs Batch Processing
When building a data pipeline, choosing the right processing method is key to meeting business needs. Real-time data processing allows businesses to instantly analyze data as it is generated, providing immediate insights and enabling faster decision-making.
This is particularly useful in situations where speed is essential, such as banking and financial services or e-commerce platforms where data updates are constantly required. On the other hand, batch processing involves collecting data in chunks at scheduled intervals, usually outside peak hours.
Although batch processing is typically slower, it is more efficient for managing large volumes of data, such as historical records, without impacting system performance. By understanding when to use real-time vs batch processing, organizations can optimize their data pipeline for specific needs, ensuring efficient handling of both structured and unstructured data.
Explore Our Data & Analytics Services
4 Key Components of a Data Pipeline
A data pipeline consists of several key components working together to move and transform data from one system to another.
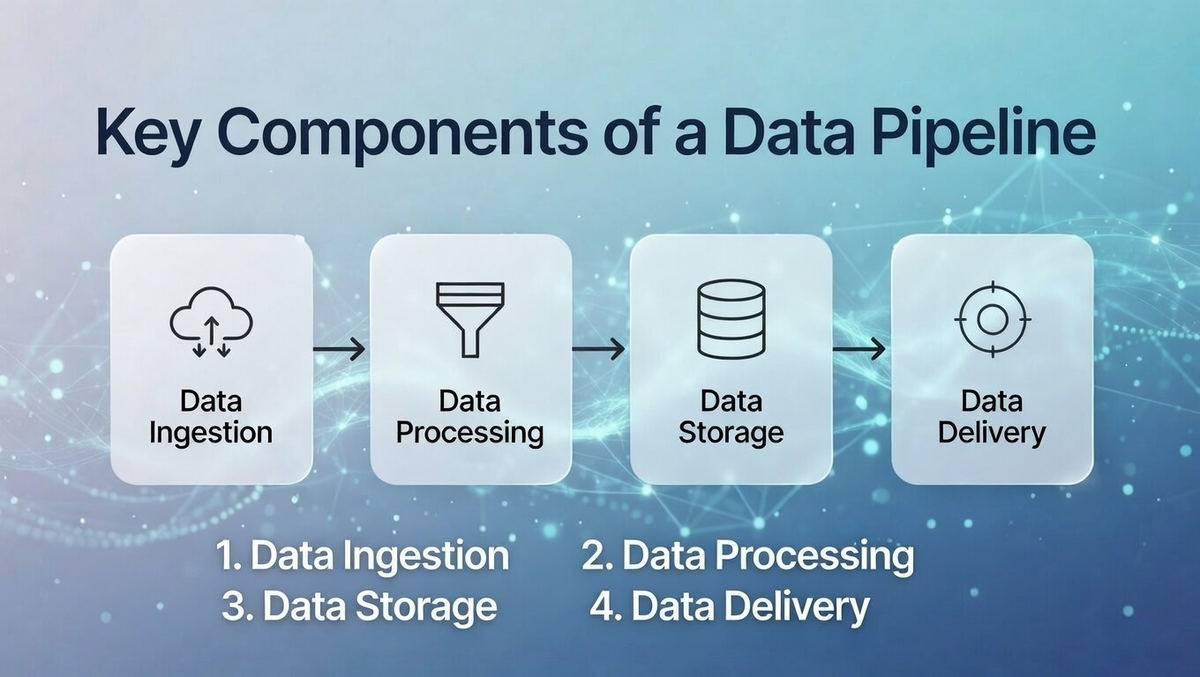
These components ensure that data is collected, processed, stored, and delivered efficiently. Let’s dive into the essential elements of a data pipeline.
1. Data Ingestion
Data ingestion involves collecting data from various sources like APIs, databases, and files. This initial step ensures that raw data is available for processing. Efficient data pipeline optimization ensures data is captured quickly, reducing latency and providing a foundation for accurate analysis downstream.
2. Data Processing
Data processing transforms and filters raw data into a structured format. Using tools like Apache Spark or Hadoop, businesses can perform aggregations, clean data, and mask sensitive information. The data transformation pipeline ensures the data is usable for analysis or integration with other systems.
3. Data Storage
After processing, data is stored in databases, data lakes, or warehouses. Cloud storage (e.g., AWS, Google Cloud) or on-premises solutions store large volumes of data. Proper data pipeline monitoring ensures data remains secure, accessible, and ready for retrieval and analysis when needed.
4. Data Delivery
Data delivery involves transferring processed data to business tools, dashboards, or machine learning models. This final stage ensures data is readily available for decision-making and analysis. Integration with business tools allows for actionable insights, driving informed decisions and operational efficiency.
4 Types of Data Pipelines
Data pipelines come in various forms, each designed to address different business needs. Understanding the different data pipeline types helps businesses choose the most suitable solution based on factors like data volume, processing speed, and real-time requirements. Let’s explore the key data pipeline types.
1. Batch Data Pipelines
Batch data pipelines process data in large chunks at scheduled intervals. This method is suitable for tasks like monthly reports or batch processing of logs. It's ideal for scalable data pipelines where real-time processing isn't necessary, helping minimize system strain during peak hours.
2. Real-Time Data Pipelines
Real-time data pipelines process data as soon as it's generated, providing immediate insights. Common in industries like finance and e-commerce, these pipelines ensure scalable data pipelines for dynamic environments. They enable quick decision-making by continuously feeding data into systems like inventory management or fraud detection.
3. Cloud-Based Pipelines
Cloud-based data pipelines process and store data over the internet, reducing reliance on on-premises infrastructure. Cloud data pipelines offer benefits such as flexibility, scalability, and cost-efficiency, making them ideal for businesses with growing data needs. They simplify management and enhance collaboration across teams and platforms.
4. Open-Source Data Pipelines
Open-source data pipelines are built using free tools and platforms like Apache Kafka and Airbyte. These pipelines offer businesses a flexible, cost-effective solution for managing data integration. Open-source platforms also allow for easy customization, enabling businesses to create scalable data pipelines tailored to specific requirements.
2 Data Pipeline Architecture
The data pipeline architecture is the backbone of any data-driven organization, determining how data flows through various stages and systems. It involves structured processes that handle everything from data ingestion to transformation, storage, and delivery.
A well-designed architecture is crucial for ensuring efficient data processing, minimizing latency, and providing real-time insights for business decisions. With advancements in data pipeline automation, organizations can ensure scalability, flexibility, and faster processing, empowering teams to make data-driven decisions at speed.
The Data Flow
The data flow within a pipeline is a systematic process that begins with data ingestion, followed by transformation, storage, and finally, delivery. The flow starts when data is collected from diverse sources such as APIs, databases, or files. Next, the data undergoes transformation, which may include cleaning, filtering, aggregating, and enriching.
After transformation, the data is stored in repositories like data lakes or warehouses for future use. Data pipeline automation plays a vital role in automating each of these steps, ensuring smoother transitions and allowing businesses to process large volumes of data efficiently with minimal manual intervention.
This flow is not just about moving data; it is about transforming it into a format that is useful, accessible, and ready for analysis. By automating the steps in the pipeline, businesses can maintain consistency in data processing and reduce human errors, which is particularly critical when working with large datasets across diverse systems.
Platform-Based Architecture
Platform-based data pipeline architecture refers to using a platform or cloud-based service (e.g., Google Cloud, AWS) to manage data flows. These platforms allow businesses to handle large-scale data operations with high flexibility and minimal overhead.
Platform-based solutions are designed to scale with the organization’s needs and offer built-in tools for data ingestion, transformation, and storage. They integrate easily with other cloud services, enabling businesses to create efficient, end-to-end data pipelines.
Using data pipeline automation in platform-based architectures provides benefits such as seamless integration, improved collaboration, and enhanced security. These platforms also allow businesses to store data in cloud-based data lakes or warehouses, offering the ability to process and analyze data in real-time or through batch processing.
This flexibility helps companies manage vast amounts of data without the need for on-premises infrastructure, reducing costs and improving scalability.
Check Our Microsoft Cloud Solutions

How to Build a Data Pipeline?
Building a data pipeline involves several crucial steps, from identifying business needs to choosing the right tools and ensuring scalability. It’s important to align the pipeline design with your business objectives, ensuring that the system is both efficient and scalable. Below are the key steps to build a successful data pipeline.
Identifying Your Business Needs
Before building a data pipeline, it’s essential to understand the types of data you’ll be handling and the volume at which it will be processed. This includes identifying whether you need batch processing or real-time data handling. Data pipeline frameworks should be selected based on your specific needs, ensuring they are flexible enough to support future growth and changes.
Understanding your business goals and requirements will guide the decision-making process, helping you choose the appropriate data sources, data models, and transformation techniques. Whether you’re processing structured or unstructured data, this step ensures your pipeline meets organizational goals.
Choosing the Right Tools
Selecting the right data pipeline tools is crucial for ensuring that your pipeline operates efficiently. Depending on the complexity of your needs, different tools offer unique capabilities. For instance, Apache Kafka and Airflow are excellent for real-time processing, while tools like Talend and Informatica are well-suited for batch processing.
Integrating the right tools helps streamline processes and ensures that data flows smoothly across various systems. Using the appropriate data pipeline frameworks helps standardize workflows, improving both scalability and flexibility, especially as data needs grow.
Implementation and Scalability
When implementing a data pipeline, it’s important to plan for scalability. This means designing a system that can efficiently handle growing data volumes over time. As your business expands, you may need to increase your pipeline’s capacity or integrate new data sources.
Scalability is a key consideration when choosing data pipeline tools and frameworks, as they must be adaptable to handle future growth. Implementing cloud-native solutions and leveraging automated scaling mechanisms ensures that your pipeline can grow with your business without losing efficiency or performance.
Data Pipeline Use Cases
Data pipelines enable businesses to process and manage data for a variety of applications, from machine learning to business intelligence. These pipelines support real-time and batch data processing, ensuring the right data is available for decision-making and operational efficiency. Here are some key use cases.
Machine Learning
Data pipelines streamline the process of feeding clean, structured data to machine learning models. They ensure that models receive consistent, high-quality data for training and real-time updates, improving the accuracy and performance of machine learning algorithms and supporting predictive analytics.
Data Migration
Data pipelines enable smooth migration of data between systems or environments. By automating the ETL process, they ensure data is accurately extracted, transformed, and loaded to the target system, making migrations seamless, faster, and less error-prone while maintaining data integrity and availability.
Business Intelligence and Reporting
Data pipelines support business intelligence reporting by ensuring timely and consistent data delivery for analysis. They enable real-time data processing and reporting, feeding data into BI tools, dashboards, and analytics platforms, which helps businesses generate insights and make informed decisions based on current and historical data.
3 Challenges in Building Data Pipelines
Building and maintaining a data pipeline comes with its own set of challenges. From handling large datasets to ensuring data quality and maintaining system reliability, overcoming these obstacles is key to ensuring a smooth data flow. Let’s look at the common challenges faced during pipeline implementation.
Handling Large Volumes of Data
One of the biggest challenges is managing large volumes of data. As businesses grow, so does the amount of data they need to process. Data pipeline optimization techniques are critical in overcoming storage and processing limitations, ensuring efficient handling of big data without causing performance issues or bottlenecks.
Ensuring Data Quality
Ensuring the accuracy and consistency of data is crucial for reliable analysis. Data pipelines must filter, clean, and standardize data as it flows through the system. By implementing data validation and quality control steps, businesses can ensure that only clean, reliable data is used for decision-making and analytics.
Monitoring and Maintenance
Regular monitoring and maintenance of data pipelines are essential for ensuring they run smoothly. Data pipeline automation tools can help track performance and detect issues in real-time. Continuous updates and improvements to pipelines are necessary to handle evolving data needs and keep systems up-to-date with the latest technologies.
FAQs
What is a data pipeline?
A data pipeline is a series of processes that collect, process, and deliver data from various sources to a destination for analysis. It ensures raw data is transformed into usable formats, helping businesses make data-driven decisions and streamline workflows effectively.
What are the types of data pipelines?
There are several types of data pipelines: batch processing, real-time processing, cloud-based, and open-source pipelines. Each type is suited to specific business needs, such as processing large data sets or enabling real-time analytics for quick decision-making and operational efficiency.
How do data pipelines help in machine learning?
Data pipelines automate the flow of data to machine learning models. They ensure that models receive clean, transformed, and structured data consistently. By feeding real-time or historical data into models, they help improve accuracy, enable better predictions, and streamline machine learning workflows.
How do you ensure data quality in a pipeline?
Ensuring data quality involves implementing steps like data validation, filtering, and cleaning within the pipeline. By using automated quality checks, businesses can eliminate inconsistencies and errors, ensuring that only accurate, reliable data is processed and used for analysis and decision-making.
Conclusion
What is a data pipeline? It’s a crucial system for efficiently managing, processing, and transforming data from multiple sources into actionable insights. As businesses increasingly rely on data for decision-making, having a well-structured data pipeline ensures data is processed, stored, and delivered in a timely and reliable manner.
In this guide, we explored the components, types, and benefits of data pipelines, including their role in machine learning, business intelligence, and data migration. We also highlighted key challenges such as handling large volumes of data and maintaining data quality.
Centric specializes in creating and optimizing data pipelines tailored to the specific needs of businesses, ensuring seamless data flow and supporting data-driven decisions. Its expertise helps organizations unlock the full potential of their data, driving growth and efficiency.






