

Curious about what is data engineering? Let’s break it down in simple terms.
Data engineering is all about building the foundation that makes data useful. It involves designing and managing the systems that collect, store, process, and prepare data so it can actually be analyzed.
Without this foundation, businesses would struggle to make sense of the massive amounts of information they generate every day.
Think of it as the plumbing behind your data. Data engineers create pipelines that move data from different sources, clean and organize it, and store it in systems like data lakes or warehouses. This ensures teams can access accurate, reliable data whenever they need it.
As companies rely more on data for decisions, the role of big data engineers becomes even more important. They handle large, complex datasets and make sure everything runs smoothly in real time.
In this guide, you’ll learn how data engineering supports modern businesses and why it’s essential for growth and smarter decision-making.
What is Data Engineering?
Data engineering is the practice of designing, building, and maintaining systems that collect, store, and process large volumes of data. It focuses on creating reliable data pipelines, managing databases, and ensuring data is clean, structured, and ready for analysis.
Using tools like ETL processes, data lakes, and cloud platforms, data engineers make sure information flows smoothly across an organization.
In today’s data-driven world, their work enables analysts and business teams to access accurate insights quickly, supporting smarter decisions and long-term growth.
What is Big Data Engineering?
Big data engineering focuses on building systems that can handle and process massive, complex datasets that traditional tools cannot manage. It ensures businesses can efficiently collect, store, and analyze large volumes of both structured and unstructured data.
Key components of big data engineering
-
Scalable Data Infrastructure: Systems designed to handle high data volume, velocity, and variety.
-
Real-Time & Batch Processing: Managing both live data streams and large historical datasets.
-
Data Storage Solutions: Using data lakes, data warehouses, and distributed storage systems.
-
Handling Structured & Unstructured Data: From financial records to social media content.
-
Advanced Analytics Enablement: Preparing data for machine learning, reporting, and business intelligence tools.
By implementing strong big data engineering solutions, businesses gain a competitive edge through faster insights and data-driven strategies.
Start Your Data Engineering & Warehousing Journey!
5 Duties and Responsibilities of a Data Engineer
Data engineers play a critical role in building and maintaining the systems that allow organizations to use data effectively.
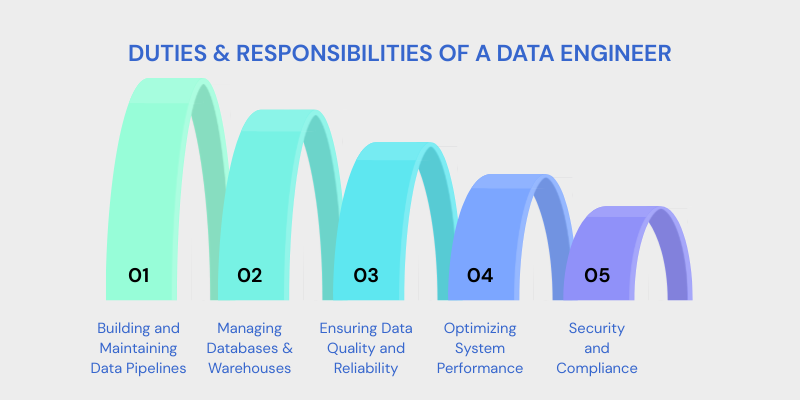
Here are data engineering duties and responsibilities:
1. Building and Maintaining Data Pipelines
Designing robust pipelines that extract data from multiple sources, transform it into usable formats, and load it into storage systems for analysis.
2. Managing Databases and Warehouses
Creating and maintaining structured storage systems that ensure fast access, reliability, and performance.
3. Ensuring Data Quality and Reliability
Implementing validation rules, monitoring systems, and data governance practices to maintain accurate and consistent datasets.
4. Optimizing System Performance
Improving query performance, tuning workflow automation, and ensuring pipelines run efficiently without bottlenecks.
5. Security and Compliance
Applying access controls, encryption, and compliance standards to protect sensitive business information.
Data Lake Engineering
Data Lake Engineering involves designing and managing large-scale storage systems that handle structured, semi-structured, and unstructured data. A data lake allows organizations to store raw data in its native format until it is needed for processing.
Key aspects of data lake engineering
-
Designing scalable cloud-based storage architectures.
-
Implementing governance and metadata management.
-
Enabling real-time and batch data processing.
-
Supporting analytics, AI technology, and machine learning workloads.
Effective Data Lake Engineering ensures businesses can store massive datasets cost-effectively while maintaining performance, security, and accessibility for advanced analytics.
Engineering Data Management System: What is it and How Does it Support Data Engineering?
An Engineering Data Management System (EDMS) is a platform designed to organize, store, and manage the lifecycle of engineering data.
These systems help engineers handle large volumes of data generated during processes like design, testing, and manufacturing.
By ensuring data consistency, structure, and accessibility, EDMS fosters collaboration across engineering teams.
Start Building Your Master Management Data System Journey!
How to Become a Data Engineer?
Becoming a data engineer involves developing a mix of technical skills and gaining hands-on experience in various data engineering tools and techniques.
Here’s a roadmap to help you on your journey:
- Learn Programming Languages: Start by learning key programming languages such as Python, Java, or Scala. These languages are essential for writing data pipelines and handling big data.
- Understand Databases and Data Modeling: A strong foundation in database engineering and data modeling is crucial. You should be proficient in SQL for relational databases (MySQL, PostgreSQL) and also understand NoSQL databases (MongoDB, Cassandra) for handling unstructured data.
- Master Data Engineering Architecture: You must understand how to design scalable data architectures that support large-scale data processing. Learn about distributed systems, data lakes, and Microsoft Cloud solutions (AWS, Google Cloud, Azure).
- Work with ETL Tools: Learn ETL (Extract, Transform, Load) processes and tools like Apache Kafka, Talend, and Apache Nifi to move data between different systems.
- Data Analytics Engineering: Develop an understanding of data analytics engineering, which involves optimizing data for analysis and ensuring data is structured properly for machine learning models and business intelligence tools.
- Cloud Platforms: Become familiar with cloud-based platforms like AWS, Google Cloud, or Azure that are often used for hosting big data solutions and data pipelines.
- Gain Experience with Data Pipelines: Learn how to automate data workflows and integrate multiple data sources for analysis. Tools like Apache Airflow, Luigi, and Azkaban are used to manage complex data workflows.
7 Data Engineering Tools and Platforms
Data engineering tools are essential for managing and processing large datasets, ensuring data quality, and optimizing data workflows.

Below are some top data engineering tools that enterprises rely on to meet their growing data management needs
1. Apache Hadoop
Apache Hadoop is one of the most popular open-source frameworks for processing large datasets in a distributed computing environment. It allows for the storage and processing of massive amounts of data across a distributed cluster, making it ideal for big data applications.
2. Apache Spark
Apache Spark is a powerful processing engine for big data workloads. It offers in-memory processing capabilities, which make it faster than Hadoop for many tasks, including data analytics, machine learning, and real-time stream processing.
3. Apache Kafka
Apache Kafka is a distributed streaming platform used for building real-time data pipelines and streaming applications. It handles high throughput, fault tolerance, and scalability, making it an essential tool for enterprises working with real-time data streams.

4. Google BigQuery
Google BigQuery is a fully-managed, serverless data warehouse that allows enterprises to run fast, SQL-like queries on large datasets. It integrates with the Google Cloud ecosystem, providing businesses with a scalable and cost-effective solution for data analysis.
5. AWS Redshift
AWS Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. It allows enterprises to analyze large amounts of data with fast query performance and scalability, often used in conjunction with AWS data lakes.
6. Talend
Talend is an open-source data integration tool that helps enterprises connect, manage, and integrate data from various sources. It offers features for ETL (Extract, Transform, Load), data quality, and data governance services.
7. Airflow (Apache Airflow)
Apache Airflow is an open-source tool for orchestrating complex workflows, particularly for managing data pipelines. It’s widely used for scheduling, monitoring, and automating ETL processes.
Applications of Data Engineering
Data engineers help retail companies by building data pipelines that integrate data from various sources, such as point-of-sale (POS) systems, inventory databases, e-commerce platforms, and customer relationship management (CRM) systems.
Key contributions of data engineers to retail include:
-
Customer Personalization: Data engineers enable personalized recommendations by processing customer data and creating user profiles based on behavior and preferences.
-
Inventory Management: They optimize inventory systems by designing data pipelines that track stock levels and predict demand, reducing overstocking or stockouts.
-
Sales Forecasting: Through real-time data processing and analysis, data engineers help retail companies predict sales trends, enabling better decision-making regarding promotions and inventory orders.
-
Supply Chain Optimization: By integrating data from suppliers, logistics companies, and retailers, data engineers help improve supply chain efficiency, ensuring the right products reach the right locations on time.
Data Engineering and Analytics
Data engineering and data analytics work hand-in-hand to provide organizations with the tools needed to make data-driven decisions.
Data engineering lays the foundation by building robust systems to collect, store, and process data. Once this infrastructure is in place, data analytics services can take over to extract insights and provide actionable intelligence.
Data engineers are instrumental in enhancing the data analytics process. Their responsibilities include:
-
Building Scalable Systems: Data engineers create scalable infrastructures that support data collection, transformation, and storage, making it easier for analysts to work with large datasets.
-
Ensuring Data Quality: By automating data cleansing, transformation, and integration, data engineers ensure that analysts always have high-quality, structured data available for analysis.
-
Optimizing Data Workflows: Data engineers continuously improve data workflows and pipelines, ensuring that analytics teams can access real-time or near-real-time data.
-
Collaboration with Data Analysts: Data engineers work closely with data analysts and data scientists to understand their data needs, providing the necessary tools and systems that enable effective analysis and reporting.
Transform Your Business with Data and Analytics!
Data Science and Engineering
Data science and data engineering are two closely related fields, yet they serve different functions within the data lifecycle.
|
Aspect |
Data Engineering |
Data Science |
Synergy |
|
Primary Focus |
Building and optimizing infrastructure to collect, process, and store data |
Analyzing and interpreting data to extract insights |
Data engineers prepare and structure data for scientists to analyze |
|
Role in Data Lifecycle |
Ensures data is clean, accessible, and scalable |
Develops models, conducts experiments, and extracts insights |
Engineers build systems that allow data scientists to focus on analysis |
|
Data Preparation |
Data engineers clean, transform, and integrate data from multiple sources |
Data scientists rely on clean, structured data to develop predictive models |
Engineers prepare data in formats suitable for analysis, enabling data scientists to work efficiently |
|
Model Deployment |
Data engineers deploy models into production systems for real-time use |
Data scientists build and train predictive models |
Engineers ensure models are scalable and work in real-time environments |
|
Automation of Insights |
Focus on automating data workflows |
Focus on automating insights derived from models |
Data science engineers ensure continuous data flow to models for real-time actionable insights |
|
Collaboration |
Provide the infrastructure and systems |
Apply analytical techniques to drive insights |
Data engineers support data scientists by ensuring high-quality data and scalable systems for insights |
5 Ways AI is Shaping The Future Of Data Engineers
Artificial Intelligence Solutions are revolutionizing data engineering by automating tasks, improving predictive capabilities, and enhancing system efficiency.
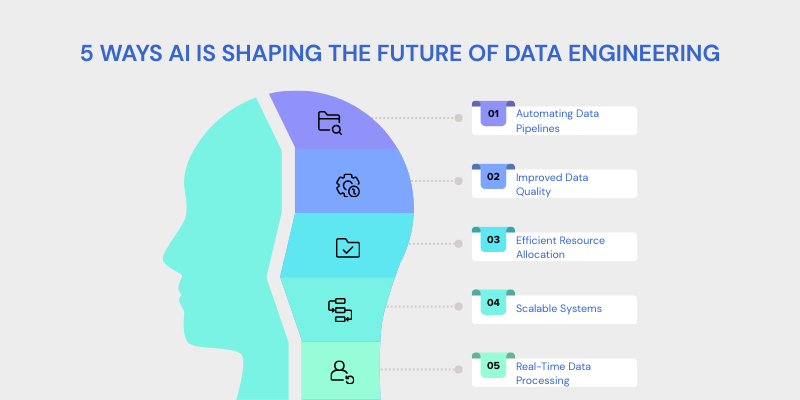
As data volume, variety, and velocity grow, AI helps data engineers optimize workflows and manage big data challenges.
Here is how AI is shaping the future of data engineering:
-
Automating Data Pipelines: AI automates data pipeline creation, cleaning, transformation, and loading, reducing manual effort and errors.
-
Improved Data Quality: AI detects anomalies and inconsistencies in data, ensuring high quality and integrity.
-
Efficient Resource Allocation: AI predicts workload spikes and allocates resources efficiently, optimizing cloud usage and reducing costs.
-
Scalable Systems: AI helps design systems that adjust to increasing data volumes, ensuring consistent performance as data scales.
-
Real-Time Data Processing: AI enables real-time data processing for instant insights, crucial for monitoring and analytics.
Start Your Artificial Intelligence Journey with Us!
Latest Data Engineering News and Trends
Data engineering is evolving fast, and 2026 is shaping up to be a big year for innovation. One of the biggest trends right now is the rise of AI-ready data infrastructure.
Companies are no longer just collecting data, they’re preparing it specifically to power AI models, automation, and advanced analytics. This means cleaner pipelines, better governance, and smarter data architecture from the ground up.
Another major shift is toward automation in data pipelines. Organizations are investing in tools that reduce manual work, improve observability, and even allow parts of the system to manage themselves. Autonomous and low-maintenance data systems are becoming a priority, especially as businesses scale.
Cloud-native and real-time processing continue to dominate. Businesses want instant insights, not reports generated days later. That’s why streaming data platforms and scalable cloud solutions are gaining momentum.
At the same time, governance and trust are getting more attention. With growing data privacy regulations and AI usage, companies are strengthening data quality, security, and compliance frameworks.
FAQs
What Does a Data Engineer Do?
A data engineer designs and manages data pipelines, creates data architectures, and ensures the efficient flow of data between systems. They work with databases, ETL processes, and big data technologies to prepare data for analysis by data scientists and analysts.
How Does Data Engineering Differ from Data Science?
While data engineers focus on creating the infrastructure and pipelines for data management, data scientists analyze the data to derive insights using statistical methods, machine learning models, and algorithms. Data engineering prepares the data, while data science interprets it.
What Tools Do Data Engineers Use?
Data engineers use tools like Apache Hadoop, Apache Spark, Talend, AWS Redshift, Google BigQuery, and Airflow for building data pipelines, processing big data, and managing data storage and analysis.
What Skills Are Needed to Become a Data Engineer?
Key skills for data engineers include proficiency in programming languages (e.g., Python, Java), knowledge of SQL and NoSQL databases, experience with big data technologies (e.g., Hadoop, Spark), and expertise in building data pipelines and cloud platforms (AWS, Google Cloud, Azure).
What Are the Benefits of Data Engineering for Businesses?
Data engineering allows businesses to manage large volumes of data efficiently, ensuring that data is clean, accessible, and ready for analysis. It enhances decision-making, improves operational efficiency, and supports real-time analytics, contributing to better customer experiences and business strategies.
Is Data Engineering a Growing Field?
Yes, data engineering is in high demand as businesses increasingly rely on data to drive decision-making. The field continues to grow with the rise of big data, AI, and cloud computing, making data engineers essential for digital transformation across industries.
Conclusion
Now that you clearly understand what is data engineering, let’s wrap it up in simple terms.
Data engineering is all about building and managing the infrastructure that allows organizations to collect, store, and process data efficiently.
It ensures data is clean, structured, and accessible for analysts, data scientists, and business intelligence teams. Without this foundation, even the most advanced analytics tools would struggle to deliver meaningful insights.
Data engineers design and maintain scalable systems, pipelines, and architectures that support the entire data lifecycle. Using ETL processes, cloud platforms, and big data technologies, they make sure information flows smoothly across the organization.
In today’s digital economy, data engineering is not optional, it’s essential. It forms the backbone of data-driven strategies, enabling smarter decisions, improved operations, and sustainable business growth for organizations like Centric.






