

Machine learning has become an integral part of modern technology, with machine learning algorithms driving advancements in everything from AI-powered personal assistants to complex data analysis systems.
In this guide, we will explore the types of machine learning algorithms that are shaping the future of technology. Understanding these ML algorithms is crucial for businesses seeking to leverage data-driven insights and automated decision-making processes.
Machine learning is transforming industries like finance, healthcare, and marketing, providing solutions that improve efficiency, reduce costs, and enhance customer experiences.
In finance, machine learning algorithms help detect fraud and predict stock market trends. In healthcare, they assist in diagnosing diseases and personalizing treatments. Meanwhile, in marketing, ML algorithms optimize ad targeting and customer segmentation.
Centric empowers businesses to adopt the right types of machine learning algorithms to stay competitive and make smarter decisions. This guide will take you through the various types of machine learning algorithms, explaining their applications and helping you choose the best fit for your needs.
What is Machine Learning?
Machine learning is a type of artificial intelligence (AI) that allows computers to learn from data and improve over time without being explicitly programmed. Unlike traditional programming, where every step is coded by humans, machine learning algorithms can adapt and make decisions based on the data they process.
These learning algorithms are designed to recognize patterns, make predictions, and continuously optimize their performance.
In traditional programming, a programmer writes specific instructions for every task. In contrast, machine learning algorithms learn from data and identify the best way to perform a task. This makes ML algo highly efficient in dealing with complex tasks that are difficult to program manually, such as image recognition or language translation.
Data plays a crucial role in machine learning algorithms categories. The more data an algorithm has, the better it can learn and improve its predictions.
Recent trends show a rapid increase in the adoption of AI technologies, with machine learning algorithms being applied across various industries, including healthcare, finance, and retail, to enhance decision-making and operational efficiency.
4 Types of Machine Learning Algorithms
In the world of machine learning, there are four main types of algorithms, each suited to different kinds of tasks. These include supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning.
The choice of machine learning algorithms depends on the problem at hand, the available data, and the specific business needs. In this blog, we will explore each of these types, discussing their key characteristics, applications, and the kind of data they require.
Each ML algorithm is designed to tackle specific challenges, and the decision of which to use depends on factors such as data type, desired outcome, and model complexity. Let’s begin with supervised learning, one of the most common types of machine learning used for predictive tasks.
1. Supervised Learning
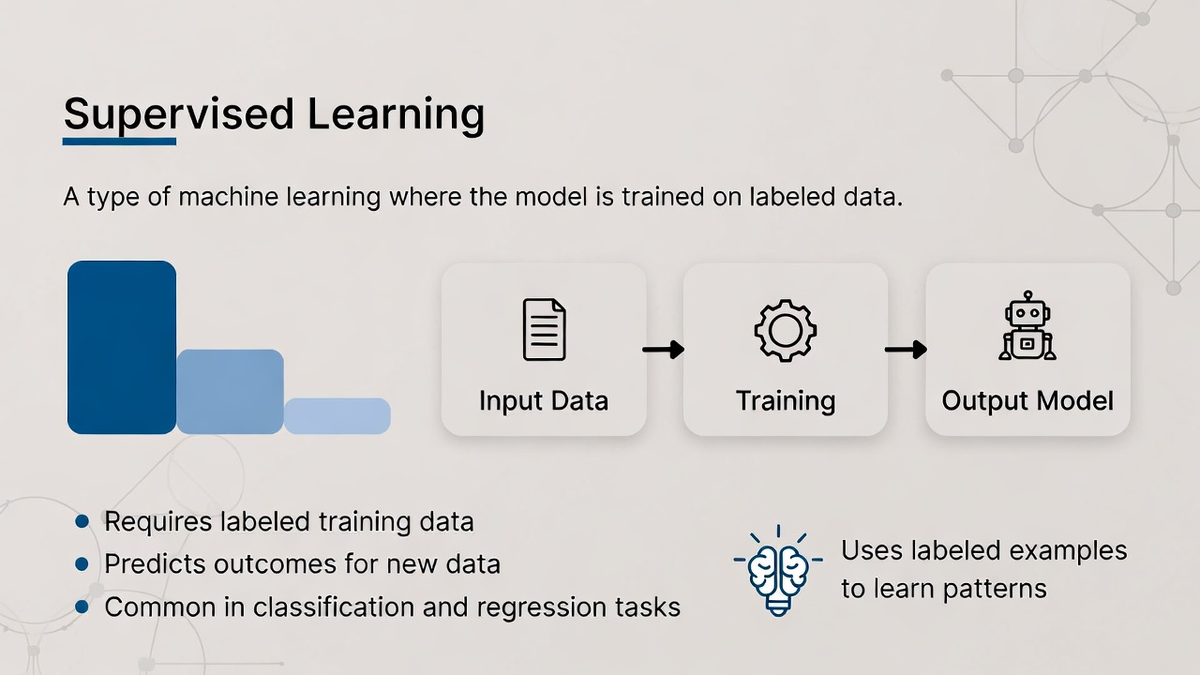
Supervised learning is one of the most fundamental learning algorithms in machine learning. In supervised learning, the algorithm is trained using labeled data, meaning that the input data comes with corresponding output labels. The goal is for the algorithm to learn a mapping from inputs to outputs and then apply that learning to new, unseen data.
The model is presented with information sets used in machine learning that contain both the input features and the expected outputs. It uses this information to adjust its parameters and make predictions. This input-output model allows the algorithm to learn from historical data, which it then uses to predict outcomes for future data points.
Examples of Supervised Learning Algorithms:
-
Classification: Classification is used when the output variable is a category, and the goal is to assign new inputs to one of those categories. For example, email spam filtering uses classification to categorize emails as "spam" or "not spam".
-
Regression: Regression is used when the output is a continuous value. It helps predict future values based on historical data. For example, predicting house prices based on factors like size, location, and amenities uses regression analysis to forecast the price of a house.
-
Forecasting: Forecasting is a technique used to predict future values, often based on historical trends. Businesses use forecasting to make predictions such as sales forecasts, demand predictions, or stock market trends.
Common Use Cases of Supervised Learning
Supervised learning is widely used across industries to address various predictive and classification challenges. Here are some common applications:
-
Healthcare: Diagnostic predictions based on medical data are a key application of supervised learning. For instance, AI models can predict disease outcomes or recommend treatments by analyzing medical records.
-
Finance: Supervised learning is widely used in fraud detection in banking and finance markets. By analyzing transaction history, algorithms can identify unusual patterns or transactions that may indicate fraud.
-
Retail: Supervised learning is used to predict customer churn in retail. By analyzing customer behavior data, retailers can predict which customers are likely to leave and take action to retain them.
Check our Banking and Finance Marketing Agency
Pros and Cons of Supervised Learning
While supervised learning is a powerful technique, it comes with its own set of strengths and limitations. Understanding these will help you determine if it's the right approach for your needs.
-
High accuracy with labeled data: One of the major benefits of supervised learning is its ability to deliver high accuracy, especially when the training dataset is large and labeled. This makes it ideal for problems like classification and regression, where the data is well-defined.
Cons:
-
Need for large labeled datasets: A major drawback of supervised learning is its reliance on large, labeled datasets. Labeling data can be expensive and time-consuming. Moreover, the performance of the model heavily depends on the quality of the labeled data, which may not always be available.
To put it in perspective, think of the logistic growth equation used in regression tasks, where we predict how certain variables evolve over time. The process of creating such models requires algorithm examples that fit the specific needs of a business.
2. Unsupervised Learning
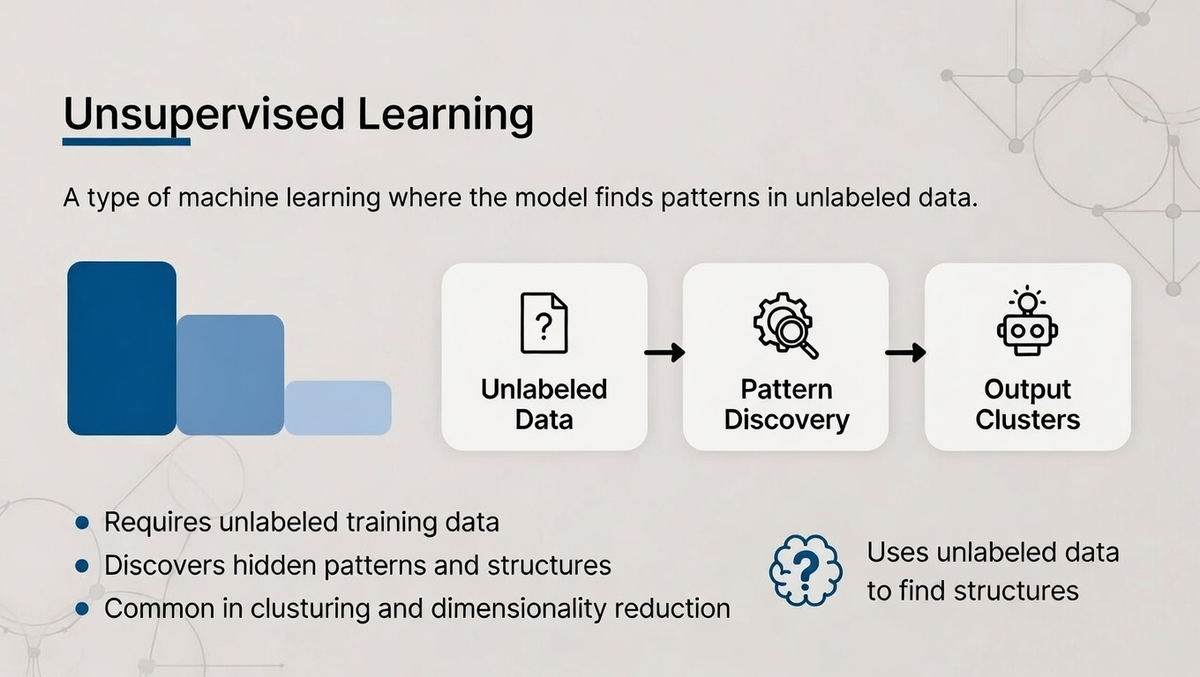
Unsupervised learning is a type of machine learning where the algorithm works with unlabeled data to find patterns and structures. Unlike supervised learning, where the model is trained on input-output pairs, unsupervised learning algorithms have no predefined labels and are left to infer relationships within the data on their own.
The goal of unsupervised learning is to identify underlying patterns, groupings, or structures in the data that might not be immediately apparent.
In unsupervised learning, the model attempts to organize the data into meaningful categories or recognize patterns that weren’t explicitly labeled.
This makes it particularly useful for exploring complex datasets where the relationships between variables are unknown. Unsupervised learning is widely applied in situations where labeling data would be too costly or time-consuming, and often leads to new insights that were previously undetected.
Key Techniques in Unsupervised Learning
Unsupervised learning techniques are essential for exploring data without predefined labels, enabling algorithms to find structures and patterns independently. These methods are particularly valuable when labeled data is scarce or unavailable, making it possible to extract insights from raw datasets.
Clustering:
Clustering is one of the most common techniques in unsupervised learning. Algorithms like K-Means and DBSCAN are used to group similar data points together based on defined criteria. Clustering helps in identifying patterns in data without the need for labels. For example, K-Means clustering can segment customers based on purchasing behavior, allowing businesses to tailor marketing strategies accordingly.
-
K-Means: An algorithm that partitions data into K groups based on similarity.
-
DBSCAN: A density-based clustering algorithm that groups data points based on density, useful for handling noise and irregular-shaped clusters.
Association:
Association algorithms like Market Basket Analysis are used to identify relationships between different variables in large datasets. These algorithms are particularly useful for discovering hidden connections between items, such as identifying which products are often purchased together in retail stores.
For instance, in e-commerce, association algorithms can suggest related items to customers based on their browsing or purchase history.
Real-World Applications of Unsupervised Learning
Unsupervised learning is widely used across various industries to gain insights from complex, unlabeled data. It helps businesses identify hidden patterns and improve decision-making without the need for pre-labeled datasets.
-
E-commerce: In e-commerce, unsupervised learning is extensively used for customer segmentation and recommendation systems. By analyzing purchasing patterns and customer behavior, businesses can target specific customer groups with personalized offers or product recommendations.
-
Healthcare: In healthcare, unsupervised learning helps with disease pattern recognition by analyzing patient data without the need for labeled information. For example, clustering algorithms can detect emerging trends in medical conditions or patient demographics, helping healthcare providers offer better treatment options.
Boost Your Sales with E-commerce Marketing
Pros and Cons of Unsupervised Learning
While unsupervised learning offers powerful capabilities for discovering patterns, it also comes with its own set of advantages and challenges. Understanding these will help businesses determine when to apply unsupervised learning effectively.
Pros:
-
Discovering hidden patterns: One of the major benefits of unsupervised learning is its ability to uncover hidden patterns in large datasets. These insights can provide valuable business intelligence, such as identifying new market segments or uncovering consumer trends that were previously unknown.
Cons:
-
Challenge of interpreting results without labeled data: A key challenge in unsupervised learning is interpreting the results. Since the algorithm works without labeled data, it can be difficult to assess the accuracy or relevance of the patterns it finds. This uncertainty makes it harder to validate the results and may require further refinement or domain expertise to interpret effectively.
To better understand how these algorithms work, consider an introduction to algorithms like K nearest neighbors (KNN), a popular unsupervised method for grouping similar data points. However, as with all ML algorithms, the performance of unsupervised learning can vary depending on the quality of the data and the chosen technique.
As businesses leverage more sophisticated ML algorithms, the ability to extract insights from complex, unlabeled data will only increase, unlocking greater potential for data-driven decisions.

3. Semi-Supervised Learning
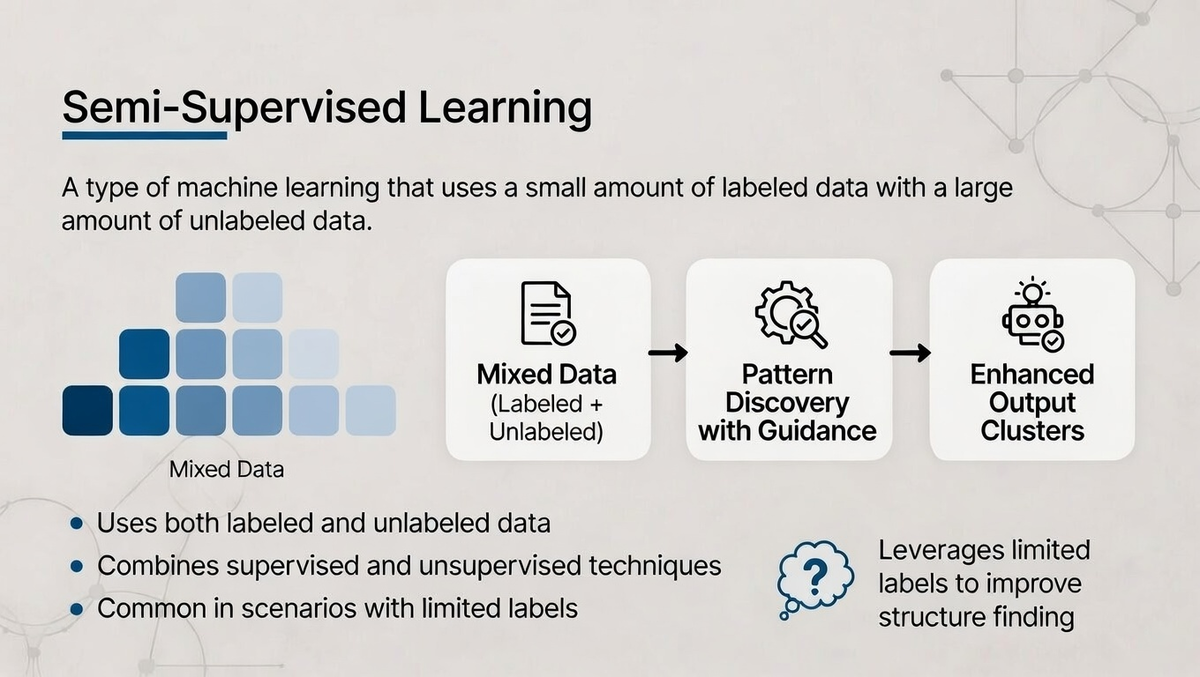
Semi-supervised learning combines the strengths of both supervised learning and unsupervised learning. It uses a small amount of labeled data along with a large amount of unlabeled data to improve the learning process.
This approach is particularly useful when labeled data is scarce or expensive to obtain, as it allows algorithms to learn from the limited labeled examples while also using the unlabeled data to improve their performance.
This method can significantly reduce the need for a large, labeled dataset, making it a more cost-effective solution for problems where acquiring labeled data is challenging. By leveraging both labeled and unlabeled data, semi-supervised learning can achieve better accuracy and generalization than using purely unlabeled data.
Key Techniques in Semi-Supervised Learning
Semi-supervised learning employs various techniques to make the most out of the available labeled and unlabeled data. These methods help to improve the accuracy of predictions and learning models while minimizing the cost of data labeling.
-
Self-training: In self-training, an algorithm begins with a small set of labeled data and uses it to predict labels for the unlabeled data. The predicted labels are then added to the labeled set, and the process repeats iteratively. This technique helps semi-supervised learning algorithms learn from both logistic growth equations and new data, thereby increasing the accuracy of the model over time.
-
Generative Models: Generative models are another key technique in semi-supervised learning. These models generate new data points based on the existing data they learn from. By creating synthetic data, generative models can enhance the training process, especially when dealing with high-dimensional regression tasks where gathering extensive labeled data is impractical.
Applications of Semi-Supervised Learning
Semi-supervised learning is highly effective in fields where data labeling is resource-intensive but still necessary for accurate results. Below are some of the key applications:
-
Medical Imaging: In medical imaging, semi-supervised learning is used to enhance diagnosis accuracy when labeled data is limited. For instance, when annotated medical scans are scarce, algorithms can learn from a small number of labeled images and vast amounts of unlabeled ones to identify patterns in medical images, improving diagnostic predictions.
-
Speech Recognition: Speech recognition systems, such as voice assistants like Siri or Alexa, use semi-supervised learning to improve their understanding of spoken language. By training on semi-labeled datasets, these systems become better at recognizing speech and understanding accents, improving user experience.
Pros and Cons of Semi-Supervised Learning
Like any machine learning technique, semi-supervised learning has both benefits and challenges. It’s important to weigh these when deciding if this approach is suitable for a given project.
Pros:
-
Reducing data labeling costs: One of the major advantages of semi-supervised learning is that it reduces the need for a large, labeled dataset. By combining a small amount of labeled data with a large amount of unlabeled data, businesses can save time and resources that would otherwise be spent on manually labeling data.
Cons:
-
Balancing labeled and unlabeled data: One challenge with semi-supervised learning is finding the right balance between labeled and unlabeled data. If there is too much unlabeled data, the algorithm may struggle to make accurate predictions. Conversely, too little labeled data can limit the algorithm’s learning ability, leading to lower model accuracy.
These benefits and challenges highlight the types of machine learning where semi-supervised learning can provide the most value, especially when dealing with high-dimensional regression problems where labeled data is sparse but unlabeled data is abundant.
4. Reinforcement Learning
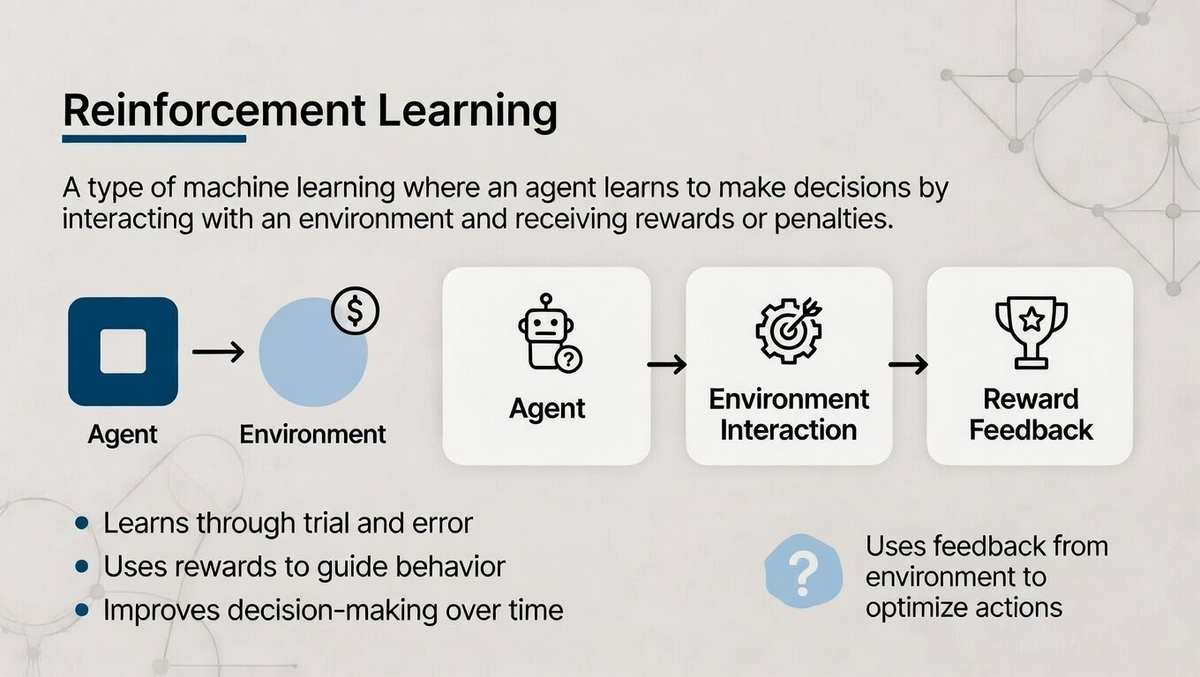
Reinforcement learning is a type of machine learning where an agent learns to make decisions by interacting with an environment. This learning process is driven by trial and error, where the agent performs actions and receives feedback in the form of rewards or penalties. The agent then uses this feedback to improve its decision-making strategy over time.
In reinforcement learning, the agent aims to maximize cumulative rewards by learning which actions lead to positive outcomes and which do not. The process is similar to teaching through rewards and penalties, where the agent improves its behavior based on past experiences, gradually becoming more efficient at achieving its goals.
Key Techniques in Reinforcement Learning
Reinforcement learning incorporates various techniques that enhance the agent's learning ability. These techniques help agents make better decisions by refining their strategies over time.
-
Q-Learning: Q-Learning is a model-free reinforcement learning algorithm that helps agents learn the optimal action to take in any given state. It works by estimating the value of each action in a state (known as Q-value), which is updated as the agent interacts with the environment. Over time, Q-Learning allows the agent to learn the best actions to take to maximize its cumulative reward, such as high-dimensional regression in decision-making tasks.
-
Deep Q-Networks (DQN): Deep Q-Networks combine reinforcement learning with deep learning to tackle more complex decision-making tasks. DQN uses neural networks to approximate the Q-values, enabling the agent to handle large state spaces that would be computationally impossible for traditional Q-Learning. This combination makes DQN particularly effective for tasks like playing video games or autonomous navigation, where the decision space is vast and dynamic.
Popular Applications of Reinforcement Learning
Reinforcement learning has found applications in several industries where decisions need to be made dynamically and autonomously. Here are some of the most notable applications:
-
Autonomous Vehicles: In autonomous vehicles, reinforcement learning algorithms help self-driving cars navigate by learning how to drive safely through trial and error. These systems learn to respond to environmental factors such as traffic lights, pedestrians, and road conditions, refining their actions for safer and more efficient driving.
-
Game AI: Reinforcement learning has gained significant attention for its use in training AI for games. An example of this is AlphaGo, an AI developed by Google DeepMind, which used reinforcement learning to master the game of Go. By learning from every move made during gameplay and adjusting its strategy accordingly, AlphaGo defeated world champions and demonstrated the power of reinforcement learning in complex environments.
Pros and Cons of Reinforcement Learning
While reinforcement learning has great potential, it also presents challenges that need to be addressed for effective implementation.
Pros:
-
Creating systems that learn autonomously: One of the major advantages of reinforcement learning is its ability to create systems that can learn from their own experiences and make decisions independently. This autonomy allows systems to adapt to changing environments, improving their performance over time without human intervention.
Cons:
-
Long training times and computational costs: The major challenge of reinforcement learning is that it often requires significant computational resources and time to train. The agent must explore various strategies, which can involve many trial-and-error steps. In environments with high-dimensional regression or complex decision-making, the training process can be lengthy and resource-intensive.
By leveraging techniques such as Q-learning and Deep Q-Networks, reinforcement learning can be applied to both simple and complex tasks, offering a powerful approach to machine learning that can drive autonomous decision-making in diverse industries.
How to Choose the Right Machine Learning Algorithm?
Choosing the right machine learning algorithm depends on several factors, including the type of data, problem complexity, and accuracy needs. For example, if you’re working with labeled data, supervised learning algorithms like decision trees or linear regression are a good choice.
For unlabeled data, unsupervised learning algorithms such as K-Means clustering work best. The complexity of the problem also plays a role—simpler tasks may benefit from basic algorithms, while complex problems may require advanced models like machine learning and deep learning.
Additionally, consider the level of accuracy required and computational efficiency. A decision matrix can help weigh these factors and guide you toward the optimal ML algorithm for your needs. It’s also important to assess the interpretability of the model, especially in industries like healthcare or finance.
Finally, the availability of computational resources can determine whether you opt for a simpler or more complex algorithm.
FAQs
What is the difference between supervised and unsupervised learning?
Supervised learning uses labeled data to train algorithms, where the output is known. It predicts outcomes based on input-output pairs. Unsupervised learning, on the other hand, works with unlabeled data, identifying patterns and structures without predefined labels, making it ideal for exploratory analysis.
How do machine learning algorithms improve over time?
Machine learning algorithms improve by learning from new data. As they receive more examples, they adjust their models through trial and error, refining their predictions and accuracy. Feedback loops, such as rewards or corrections, help algorithms continually optimize their performance and decision-making ability.
What are the best tools for implementing machine learning algorithms?
The best tools for implementing machine learning algorithms include TensorFlow, Scikit-learn, Keras, PyTorch, and XGBoost. These platforms offer extensive libraries and frameworks for training, testing, and deploying various ML algorithms. Each tool suits different needs, from deep learning to simpler regression models.
How can machine learning benefit businesses?
Machine learning helps businesses by automating decision-making, improving customer experiences, and increasing efficiency. It can predict trends, detect anomalies, personalize marketing, and optimize operations. By leveraging ML algorithms, companies can make data-driven decisions, enhance product recommendations, and streamline processes, leading to increased profitability.
Conclusion
As the world of technology continues to evolve, the types of machine learning algorithms are becoming more advanced, with growing integration into industries such as healthcare, finance, and e-commerce.
The future trends point toward increased use of AI algorithms to automate tasks, enhance personalization, and optimize business operations. With innovations like deep learning and reinforcement learning, businesses can expect more intelligent systems capable of handling complex, dynamic environments.
Centric helps businesses adopt the most suitable machine learning models, guiding them through the process of integrating AI into their operations.
By doing so, it enables organizations to leverage the power of data-driven insights, drive innovation, and gain a competitive advantage. Embracing these technologies will allow businesses to stay ahead of the curve in an increasingly data-centric world.






